Lexique illustré des termes de l’intelligence artificielle
Mickaël Wajnberg, Ph.D.
il y a 5 ans
Intelligence artificielle, apprentissage machine, apprentissage profond, fouille de données... Ces termes sont de plus en plus omniprésents dans notre quotidien, mais souvent employés de manière confuse et imprécise. Cet article vise à aider des non-spécialistes à naviguer avec plus de confiance entre les termes.

Intelligence artificielle
L’intelligence artificielle (IA) est définie par l’encyclopédie du Larousse en ligne comme étant l’ ”ensemble de théories et de techniques mises en œuvre en vue de réaliser des machines capables de simuler l’intelligence humaine”. Toutefois, cette définition ne reflète que très partiellement la réalité des scientifiques du domaine. L’IA est un domaine complexe qui s’est intéressé principalement à deux grandes dimensions.
L’IA est un domaine complexe qui s’est intéressé principalement à deux grandes dimensions. Tout d’abord, dans le domaine, une première question est à se poser, l’intelligence est-elle finalement définie par les capacités de l’Homo Sapiens ou de manière plus abstraite par la rationalité et la logique? Il en découle ensuite une interrogation sur le support de cette intelligence : est-ce que le résultat, c’est-à-dire le comportement vu de l’extérieur, peut-être une preuve d’intelligence ou faut-il examiner aussi le processus interne de la réflexion ?
En croisant les deux axes : (1) humain vs rationnel (2) comportement vs processus interne, on obtient donc quatre définitions possibles pour le domaine de l’IA, chacune ayant donné naissance à un folklore complet de recherche.
-
Comportement humain Selon Alan Turing, et son test proposé en 1950, on peut définir une entité comme intelligence artificielle à partir du moment ou un humain n’est pas capable de faire la distinction entre une communication avec un autre humain ou la machine testée. Le test est le suivant : on place un candidat en communication par message avec une entité humaine et une machine, si le candidat ne peut dire avec certitude laquelle de ces entités est la machine, le stade d’intelligence artificielle est atteint.
-
Pensée humaine Ici, l’intelligence artificielle est à la croisée des mondes de l’informatique et des sciences cognitives. L’idée n’est pas simplement d’observer le résultat donné par la machine, mais d’étudier d’un point de vue psychologique les décisions intermédiaires prises pour évaluer le raisonnement général et créer une machine dont le fonctionnement interne serait similaire à l’humain.
-
Pensée relationnelle Le but des IA de pensée rationnelle est de suivre le plus fidèlement les règles de déduction qui ont commencé à émerger depuis la Grèce antique. En effet, l’exemple le plus connu est sûrement le syllogisme «Socrates est un homme, tous les hommes sont mortels, donc Socrates est mortel». Toutefois, ces règles ne se limitent pas à des syllogismes, car les faits réels sont rarement noirs ou blancs. Les approches les plus modernes combinent les règles formelles (syllogismes) avec la gestion des probabilités.
-
Comportement rationnel À l’opposé complet de la définition du Larousse, ce sous-domaine de l’IA est pourtant le plus important (en matière de productivité, taille de la communauté, nombre d’articles publiés, etc.). Il consiste à créer des agents, c’est-à-dire des entités qui agissent de manière rationnelle, et ce, sans restriction sur le mode de fonctionnement des processus internes. Ces agents sont définis pour répondre à un besoin précis et, prenant compte de son environnement et des contraintes imposées, visent à maximiser le résultat vis-à-vis de ce besoin.
L’agent rationnel
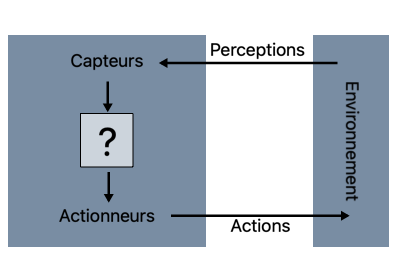
Figure 1
Un agent est un système qui perçoit son environnement (virtuel ou non) à l’aide de capteurs, calcule le meilleur rendement selon ses contraintes et objectifs, puis agit.
Par exemple, un adversaire automatique aux échecs perçoit le plateau, prend la décision qui l’amènera le plus sûrement à la victoire, puis déplace une pièce.
L’agent reflex
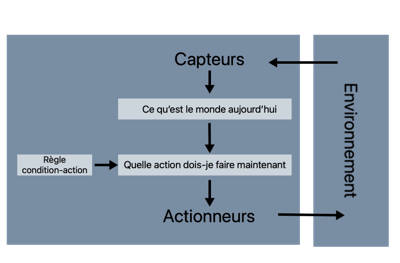
Figure 2
Les agents les plus simplistes sont simplement des agents dits «réflexes», c'est-à-dire ayant un ensemble de règles édictées à l’interne qu’ils suivent de manière absolue, tel qu’illustré ci-dessus.
Aux échecs, cela reviendrait à enregistrer tous les coups possibles pour toutes les configurations de plateau et choisir le meilleur coup...
Les agents réflexes sont limités à des cas plus simples comme celui d’un aspirateur automatique : S’il y a de la poussière sous l’aspirateur, faire l’action d’aspirer, s’il y a de la poussière ailleurs, faire l’action de se déplacer, sinon retourner l’aspirateur au point de charge.
Deux évolutions naturelles (qui peuvent tout à fait se combiner) à ces agents ont émergé.
La première, sur laquelle on ne s’attardera pas ici, est la notion d’agents logiques. À l’instar des agents réflexes, les agents logiques ont aussi un ensemble de règles encodées. Toutefois, les agents logiques ne portent pas des règles au cas par cas. Les règles de l’agent sont des règles de raisonnement, il porte aussi une «représentation interne du monde». En communiquant les informations sur le monde, les informations sur l’état actuel de son environnement immédiat, l’agent logique va concevoir automatiquement la solution.
Toujours en suivant l’analogie du jeu d’échecs, plutôt que de stipuler «lorsque la Dame est en g1, le roi ennemi en g8 et que le fou est en h6, jouer la dame en g7» et tous les autres cas. On intègre simplement au processus de l’agent «si victoire possible au prochain tour, procéder au mouvement mettant en mat», et on laisse l’agent calculer si un échec et mat est effectivement possible dans l’environnement possible (l’état du plateau) en connaissant les informations du monde (les règles du jeu, particulièrement le déplacement des pièces).
La seconde est un agent apprenant. Considérons la figure 3. Bien que la partie «performance» reste sensiblement la même ( un ensemble de règles à suivre ), ces règles sont modifiées par les exemples que le système rencontre.
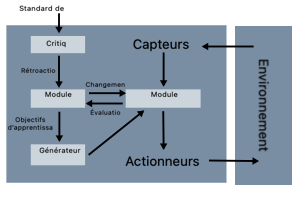
Figure 3
On rencontre donc trois nouveaux blocs ici :
- un bloc d’apprentissage, responsable d’améliorer les règles,
- un bloc de critique qui permet de donner à l’agent un retour sur les règles mises en place et
- un bloc de génération de problème qui permet de modifier les objectifs pour trouver un équilibre entre (1) répondre au besoin initial de l’agent et (2) découvrir de l’information pertinente.
Illustrons par l’image d’un robot équipé d’une boussole et de coordonnées d’arrivée. Initialement, le robot va se déplacer tout droit vers l’objectif, mais s’il rencontre un obstacle, le générateur de problème va définir des objectifs annexes, comme tourner à 90 degrés, pour obtenir de l’information et possiblement trouver un nouveau chemin.
Apprentissage machine et fouille de données
Comme on vient de le voir, les intelligences artificielles peuvent être construites sous la forme d’agents apprenants. Et qui dit agent apprenant, dit apprentissage machine (ML pour Machine Learning).
L’apprentissage machine est une discipline qui, malgré les mystères qui planent autour, étend simplement les approches probabilistes et statistiques à des problèmes de géométrie.
Les deux plus grandes classes de ML sont l’apprentissage supervisé et non supervisé. Pour se donner une intuition imaginons un ensemble de points dans l’espace (par exemple le capital de clients en fonction de leur âge).

Figure 4
Le supervisé correspond au graphique ci-dessus où les points ont des étiquetages distincts «x» et «o» (par exemple on note si les clients sont francophones ou anglophones). Dans un tel cas, le but d’un système de ML est de créer une fonction (tracer une ligne par exemple) séparant les deux catégories. Cette fonction, qu’on appelle modèle, permet de faire a posteriori des prédictions pour une nouvelle donnée entrante : on compare sa position au modèle pour déterminer la catégorie la plus probable de son étiquetage («o» ou «x»).
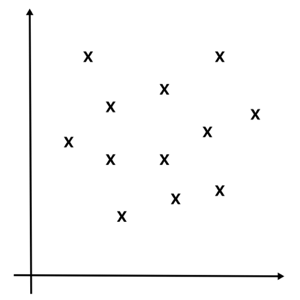
Figure 5
Dans le cadre d’une application non supervisée, on ne considère aucune caractéristique comme prévalente sur les autres, c'est-à-dire qu’il n’existe pas d’étiquette d’apprentissage, tous les points sont dans la même catégorie, comme dans le graphique de droite. Dans un tel cas, une des approches possibles est que la machine va créer des groupes en utilisant la proximité des points. On peut tout à fait imaginer, sur ce second graphique, trois groupes, le premier prenant les quatre points en bas à droite, le second les quatre en bas à gauche et le dernier les quatre points du haut.
Que l’apprentissage soit supervisé ou non, il repose d’abord et avant tout sur la découverte de régularités dans les données (par exemple un positionnement dans l’espace). La fouille de données est le domaine englobant les algorithmes qui permettent la découverte de régularités.
La fouille de donnée est le domaine qui vise à extraire les régularités d’un jeu de données, l’apprentissage machine est le domaine qui, à partir de régularités découvertes dans les données, vise à éditer des règles d’action pour un système et l’intelligence artificielle est le domaine permettant la création d’agents rationnels qui peuvent utiliser le ML.
Les trois disciplines sont indépendantes bien que fortement connexes.
Réseaux neuronaux et apprentissage profond
À l’heure actuelle, une confusion est souvent faite entre «intelligence artificielle» et «apprentissage profond» (qu’on voit plus écrit sous sa forme anglo-saxonne «deep learning» (DL)). Pour donner une intuition au non-initié à la notion de DL, il nous faut commencer par présenter ce qu’est un réseau de neurones ainsi qu’un neurone. Bien sûr, ici, on fait une présentation introductive sans présenter les mathématiques derrière.
Réseau de neurones artificiels
Le neurone artificiel, aussi appelé neurone formel, peut être perçu comme une régression.
Utilisons l'illustration suivante pour expliquer le principe.
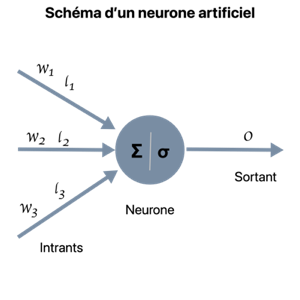
Figure 6
Un neurone, à l’instar de la régression, peut être considéré comme un système d’apprentissage supervisé.
Par exemple, dans le cas de l'illustration du contexte supervisé (figure 4), le neurone va apprendre les caractéristiques (angle et position) de la droite séparant les «x» des «o», puis se servira de cette droite pour prédire la classe de toute nouvelle entrée comme n’importe quel système de ML.
Le neurone est composé de plusieurs parties
- un ensemble d’entrées, qui correspondent aux coordonnées des points à considérer. Par exemple une entrée correspond à l’âge et l’autre entrée au capital d’un client.
- ces entrées sont connectées par les flèches de gauche au neurone. En passant par les flèches, les entrées sont multipliées par un coefficient propre à chaque flèche. Les coefficients jouent le rôle de marqueur d’importance de l’entrée, par exemple si le capital d’un client est 9 fois plus important que son âge pour décider s’il est anglophone ou francophone, le coefficient du capital serait 0.9 alors que celui de l’âge 0.1. Finalement l’ensemble des coefficients permet de définir l’équation d’une droite qui sert de modèle.
- la partie gauche du neurone, la sommation, fait la somme des entrées (après multiplication par l’importance). Cela permet d’obtenir un nombre reflétant la position relative du point d’entrée (la position du point du client) par rapport à la droite internalisée par le neurone (en dessous ou au-dessus).
- la partie droite du neurone est ce qu’on appelle la fonction d’activation. C’est-à-dire la fonction qui, prenant en compte la position relative indiquée, affectera la classe finale («x» ou «o») à l’entrée fournie. Les fonctions d’activation peuvent être simples (par exemple, si le point est au-dessus de la droite mettre un «x» sinon un «o») ou probabilistes (par exemple, plus le point est proche de la droite plus le score fourni est proche de 50-50 et plus il s’éloigne vers le haut plus on se rapproche d’un 100-0).
Lors de la phase d’apprentissage, le neurone teste tous les points connus de son modèle (le choix des coefficients définissant la droite séparant «x» et «o») et confronte le résultat attendu à sa prédiction. À chaque erreur, les coefficients sont ajustés jusqu’à avoir trouvé la droite parfaite (ou à défaut, celle qui permet le moins d’erreurs).
L’intérêt de ne pas visualiser mathématiquement les neurones comme des régressions, mais bien comme dans la figure 5, est qu’il devient facile de connecter des neurones en chaîne : la sortie d’un neurone est envoyée dans l’entrée d’un autre. Une telle construction s’appelle un réseau de neurones tel qu’illustré ci-dessous.

Figure 7
Apprentissage profond (Deep Learning)
Le Deep Learning (DL) constitue simplement le domaine d’application des réseaux de neurones dits profonds. Dans la figure 6, on constate que certains neurones sont directement connectés aux entrées réelles, certains sont directement reliés aux sorties et d’autres sont entre les entrées et sorties, uniquement connectés à d’autres neurones, d’un côté comme de l’autre. On qualifie ces neurones de «cachés». Ce qui caractérise le DL c’est la profondeur du réseau, en d’autres termes le nombre d’étapes (de transformations) dans les couches cachées qu’un signal d’entrée doit faire pour atteindre la sortie (ici trois). On considère un réseau comme profond dès qu’il y a au moins une couche cachée (certains argumenteront pour deux ou trois couches, mais l’idée reste la même).
L’intérêt de cette profondeur est la possibilité de combiner les caractéristiques des entrées de manière hiérarchique. Imaginons un cas d’application d’un réseau détectant sur des images 1080 pixels si c’est une fourchette ou un humain qui est représenté. La couche d’entrée intégrera les 1080 pixels, la première couche va permettre de détecter des segments de droites (chaque neurone sera responsable de tester un segment qui lui sera propre), la seconde couche va détecter des angles et des courbes (chaque neurone prendra en charge la détection d'un angle ou d'une courbe différents), la couche suivante aura des caractéristiques plus reconnaissables (nez, manche, bouche, dents, ...) et finalement la couche de sortie, au lieu de recevoir l’image, va recevoir un ensemble de caractéristiques (telles que "l’image comporte un nez et une bouche") puis va pouvoir prendre la décision.
Conclusion
Comme nous avons pu le voir, l’IA est un domaine vaste qui peut entre autres se reposer sur l’apprentissage machine, qui lui-même repose sur l’utilisation de régularités découvertes par des algorithmes de fouille de données. L’apprentissage machine est un domaine vaste contenant de nombreuses techniques dont l’apprentissage profond, un domaine construit sur les réseaux de neurones ayant de nombreuses couches cachées.
Références:1 Yoshua Bengio, Ian Goodfellow, and Aaron Courville. Deep learning, volume 1. MIT press Massachusetts, USA:, 2017.
2 Nils J Nilsson. The quest for artificial intelligence. Cambridge University Press, 2009.
3 Stuart Russell and Peter Norvig. Artificial intelligence: a modern approach. 2002.