Découverte de connaissances et fouille de données
Mickaël Wajnberg, Ph.D.
il y a 5 ans
De nos jours, la production de données est colossale. Bien que les chiffres pour l’année 2021 ne soient pas encore disponibles, une étude de BSA, disponible sur le site de l’entreprise Microsoft, affirme que déjà en 2016, 2.5×1030 octets de données étaient générées chaque jour, avec une tendance croissante.1

Toujours selon BSA, elles sont, entre autres, le nerf de la guerre pour «la croissance économique, pour le développement de l’agriculture, pour les décisions politiques et pour la gestion des énergies renouvelables». Une meilleure gestion des données produites, même sensible, peut avoir un impact considérable. En effet, Microsoft1 et General Electric4 mentionnent que les économistes s’accordent pour dire que l’amélioration de la compréhension et la gestion des données de seulement 1% pourrait augmenter le PIB international de 15 billions de dollars américains. Ainsi, actuellement, 90% des grandes entreprises citent les données comme une ressource-clé1, justifiant l’émergence du domaine de la découverte de connaissance ayant pour objectif de donner du sens aux données.
Les méthodes «traditionnelles», pour transformer les données en connaissances, se reposent sur une équipe d’analystes devenant familiers avec les données et servant d’interface avec les utilisateurs. Toutefois, avec l’accroissement des tailles et de la complexité des jeux de données et (il est maintenant commun de trouver des jeux de données regroupant des milliards d’entrées avec des centaines/milliers de caractéristiques chacune, et chacune de ces entrées peut être connectée à plusieurs autres) les analyses manuelles sont difficiles, longues, coûteuses et hautement subjectives.
La découverte de connaissance est maintenant appliquée dans des domaines nombreux et variés, tels que la manufacture avec l’apparition de l’industrie 4.0, les finances avec les algorithmes de «hedge funds», le marketing pour la conception de systèmes de recommandation, la détection de fraude, l’astronomie...
##De la fouille de données à la découverte de connaissance On retrouve parfois une certaine confusion entre les termes de fouille de données, en anglais data mining, et la découverte de connaissances.
Toutefois, le processus de découverte de connaissance est plus large que la fouille de données, qui n’en est qu’une étape (ceci-dit, sans doute la plus importante).
La discipline de la découverte de connaissances évolue en même temps que les champs dont elle se retrouve à l’intersection : le machine learning, l’intelligence artificielle, les statistiques, la visualisation de données et l’optimisation.
Ainsi, la découverte de connaissances se concentre sur le processus général d’extraction de connaissance puisqu’elle a été définie comme «le processus non-trivial d’identifier dans les données des régularités valides, nouvelles, potentiellement utiles, et compréhensibles»3. En ce sens, elle élargit la logique des statistiques puisque, d’une part, elle vise à produire un langage et un cadre pour inférer des régularités d’un échantillon à la population globale tout en produisant des métriques pour quantifier l’incertitude de ces généralisations, et d’autre part elle vise à automatiser le processus complet incluant tant l’«art» de la sélection d’hypothèses que l’analyse des données2. Elle ne se limite donc pas à la discipline de fouille de données qui trouvera toujours des régularités statistiquement significatives dans des jeux de données assez larges, même dans des jeux de données complètement aléatoires ou toute régularité est purement fortuite5.
Il est toutefois à noter ici que la notion de «connaissances» n’a pas de prétention philosophique.
En effet, tel que présenté à la figure 1 ci-dessous, si l’on considère les faits connus par le système (les données), on qualifie d’information les régularités, c’est-à-dire les descriptions d’agglomérations de ces données, et de connaissances les informations significatives et nouvelles qui dépassent un seuil d’intérêt, la notion d’intérêt ainsi que le seuil étant fixé par l’utilisateur, dépendamment du domaine et de l’application.
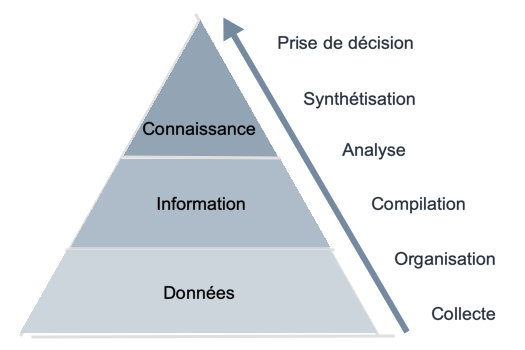
Figure 1
Le processus général de la découverte de connaissance est dépeint à la figure 2. Il est itératif et composé de 9 étapes qui peuvent à tout moment demander un retour en arrière.
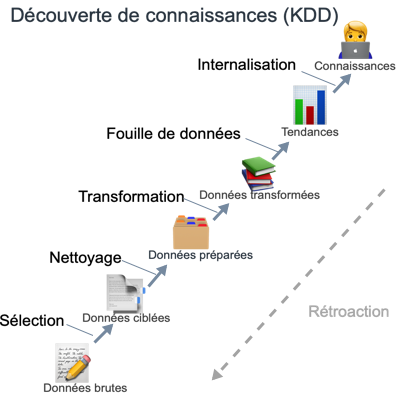
Figure 2
Après avoir défini un objectif pour le processus (1), un ensemble de données est sélectionné pour être confronté au processus (2). Les données sont alors nettoyées (suppression du bruit et traitement des valeurs manquantes) (3) et réduites au besoin (par PCA par exemple) (4). On choisit alors la méthode de fouille de données correspondant à l’objectif visé (5) puis l’algorithme implémentant de manière optimale cette méthode selon les données (6). L’application de l’algorithme aux données (7) permet d’extraire des régularités qui sont alors filtrées et interprétées (par exemple à l’aide d’outils de visualisation de données) (8). Finalement, on peut utiliser les connaissances extraites (9) pour raffiner le processus, en les intégrant dans un autre système ou simplement dans une documentation pour un utilisateur (telle que les «dash boards»).
##Objectifs et méthodes Tel que l’on vient de le souligner, le processus dépend grandement de l’objectif que l’on se fixe. Les trois applications les plus largement répandues sont :
- la vérification d’hypothèses, qui correspond au processus général associé aux statistiques ;
- la prédiction, on demande au système de découvrir des régularités qui serviront à anticiper le comportement de données inconnues (ou des variations des données déjà intégrées dans le cas de systèmes dynamiques) ; et
- la description, pour laquelle le système extrait des régularités pour les présenter à un utilisateur humain (la compréhensibilité est alors l’une des préoccupations principales)2.
Pour répondre à de tels objectifs, il existe de multiples méthodes que nous ne pouvons couvrir exhaustivement ici. Toutefois, pour donner au lecteur une intuition des grandes familles d’approche, elles sont sommairement illustrées ci-dessous.
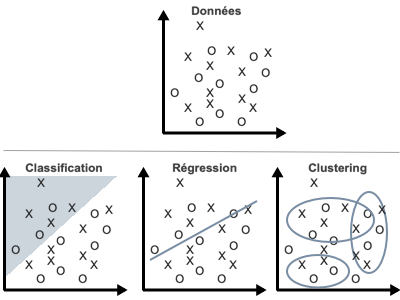
Figure 3
La classification consiste à ordonner des données selon leur similarités.
La régression est une méthode statistique qui tente de déterminer le type et la force des corrélations entre une variable donnée et une série d’autres variables indépendantes.
Le clustering consiste à regrouper ensemble les points qui présentent des caractéristiques communes.
Références: 1 BSA. What’s the big deal with data? http://download.microsoft.com/documents/en-us/sam/ bsadatastudy_en.pdf, 2016. Accessed: 2020-04-17. 2 Usama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. From data mining to knowledge discovery in databases. AI magazine, 17(3):37–37, 1996. 3 Usama M Fayyad, Gregory Piatetsky-Shapiro, Padhraic Smyth, and Ramasamy Uthurusamy. Advances in knowledge discovery and data mining. American Association for Artificial Intelligence, 1996. 4 G.E. Industrial internet: Pushing the boundaries of minds and machines. http://les.gereports.com/wp-content/uploads/2012/11/ge-industrial-internet-vision-paper.pdf, 2012. Accessed: 2020-04-17. 5 Gary Smith and Jay Cordes. The 9 pitfalls of data science. Oxford University Press, 2019.